A engenharia de recursos e a extração de recursos são chaves – e demoram – partes do fluxo de trabalho de aprendizado da máquina. Trata-se de transformar dados de treinamento e aumentá-lo com recursos adicionais para tornar os algoritmos de aprendizado de máquinas mais efetivos. O aprendizado profundo está mudando, de acordo com seus promotores. Com o aprendizado profundo, pode-se começar com dados brutos, uma vez que os recursos serão criados automaticamente pela rede neural quando descobrirem. Por exemplo, veja este trecho da Deep Learning and Feature Engineering :
A abordagem de engenharia de recursos foi a abordagem dominante até recentemente, quando as técnicas de aprendizado profundo começaram a demonstrar desempenho de reconhecimento melhor do que os detectores de recursos cuidadosamente criados. A aprendizagem profunda muda o fardo do design de recursos também para o sistema de aprendizagem subjacente, juntamente com o aprendizado de classificação típico da aprendizagem de redes neurais de camada múltipla anterior. Nesta perspectiva, um sistema de aprendizado profundo é um sistema totalmente treinável a partir da entrada bruta, por exemplo pixels de imagem, para a saída final de objetos reconhecidos .
Como de costume com declarações ousadas, isso é verdadeiro e falso. No caso do reconhecimento de imagem, é verdade que muita extração de recursos tornou-se obsoleta com aprendizado profundo. Mesmo para o processamento de linguagem natural, onde o uso de redes neuronais recorrentes também obteve muito engenharia de recursos obsoleto. Ninguém pode desafiar isso.
Mas isso não significa que o pré-processamento de dados, a extração de recursos e a engenharia de recursos são totalmente irrelevantes quando se utiliza aprendizagem profunda.
Deixe-me tomar um exemplo por causa da clareza, tirado da recomendação de música no Spotify com aprendizado profundo . Eu recomendo ler este artigo, pois introduz um aprendizado profundo e como ele é usado em um caso particular muito bem.
Não vou explicar o aprendizado profundo em geral. Basta dizer que a aprendizagem profunda é mais frequentemente implementada através de uma rede neural de várias camadas. Um exemplo de uma rede neural é dado no artigo acima:
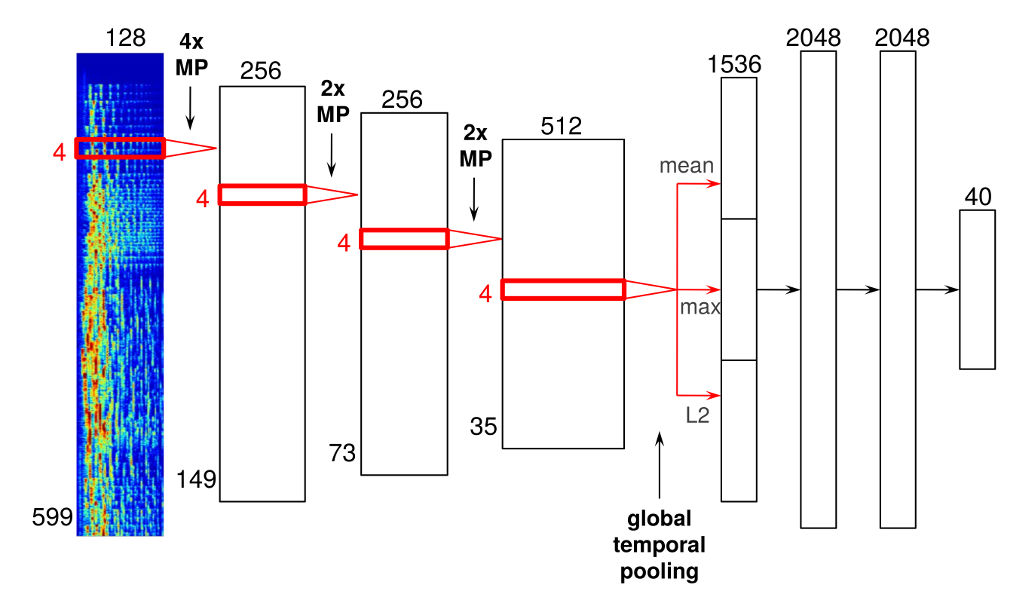
O fluxo de dados da esquerda para a direita. A camada de entrada, a camada mais à esquerda, recebe uma codificação de músicas. As próximas três camadas são camadas de pool máximo. A próxima camada calcula a média, máx. E a norma L2 de seus dados de entrada. As próximas três camadas são camadas convolucionais e a última camada é uma camada de agrupamento temporal.
Não se preocupe se você não entender completamente o que tudo isso significa. O ponto chave é que a aprendizagem só acontece entre as três camadas convolutivas. Todas as outras camadas são extração de recursos com codificação rígida e engenharia de recursos codificados. Deixe-me explicar o porquê:
Este exemplo é uma rede neural onde a maior parte da rede é uma engenharia de recursos com código rígido ou alguma extração de recursos codificados. Eu escrevo com código rígido, pois estes não são aprendidos pelo sistema, eles são predefinidos pelo designer de rede, o autor do artigo. Quando essa rede aprende, ela ajusta pesos entre suas camadas convolucionais, mas não modifica os outros arcos na rede. Aprender apenas acontece por 2 pares de camadas, enquanto nossa rede neural possui sete pares de camadas consecutivas.
Este exemplo não é uma exceção. A necessidade de pré-processamento de dados e engenharia de recursos para melhorar o desempenho do aprendizado profundo não é incomum. Mesmo para o reconhecimento de imagens, onde o primeiro sucesso de aprendizagem profunda aconteceu, o pré-processamento de dados pode ser útil. Por exemplo, encontrar o espaço de cores certo para usar pode ser muito importante. O agrupamento máximo também é usado muito nas redes de reconhecimento de imagens.
A conclusão é simples: muitas redes neurais de aprendizagem profunda contêm processamento de dados codificados, extração de recursos e engenharia de recursos. Eles podem exigir menos destes que outros algoritmos de aprendizagem de máquinas, mas eles ainda exigem alguns .
Eu não sou o único que declara o acima; veja este artigo, por exemplo .
 +1-786-628-7980
+1-786-628-7980
 Sign Up/Sign In
Sign Up/Sign In