No início desta semana, a AWS anunciou a disponibilidade do Model Server para o Apache MXNet, um componente de código aberto incorporado ao Apache MXNet para servir modelos de aprendizado profundo. O Apache MXNet é uma estrutura de treinamento e inferência rápida e escalável com uma API concisa e fácil de usar para aprendizagem em máquina. Com o Model Server para o Apache MXNet, os engenheiros agora podem servir modelos MXNet de forma fácil, rápida e em escala.
O Servidor de Modelos para o Apache MXNet (MMS) é um componente de código aberto que foi projetado para simplificar a tarefa de implantação de modelos de aprendizagem profunda para inferência em escala. A implantação de modelos para inferência não é uma tarefa trivial. Requiere coletar os vários artefatos do modelo, configurar uma pilha de serviços, inicializar e configurar a estrutura de aprendizado profundo, expor um ponto final, emitir métricas em tempo real e executar o código personalizado pré-processamento e pós-processamento, para mencionar apenas alguns as tarefas de engenharia. Embora cada tarefa possa não ser excessivamente complexa, o esforço geral envolvido na implantação de modelos é significativo o suficiente para tornar o processo de implantação lento e pesado.
Com o MMS, a AWS contribui com um conjunto de ferramentas de engenharia de código aberto para o Apache MXNet que simplifica drasticamente o processo de implantação de modelos de aprendizado profundo. Aqui estão as principais capacidades que você obtém usando o MMS para implantação do modelo:
O MMS está disponível para uso através de um pacote PyPi , ou diretamente do repositório GitHub do Servidor Modelo , e ele é executado no Mac e no Linux. Para casos de uso de produção escaláveis, recomendamos o uso das imagens Docker pré-configuradas que são fornecidas no repositório MMS GitHub.
Uma arquitetura de referência de exemplo é ilustrada no seguinte diagrama:
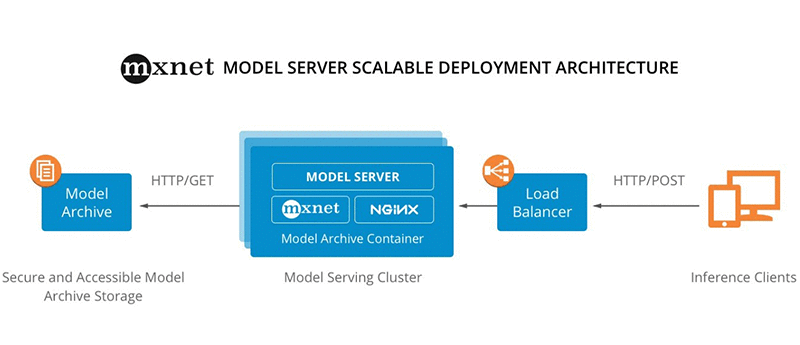
Começar com o MMS é fácil, como demonstraremos no exemplo a seguir. Este exemplo aproveita um modelo pré-treinado de detecção de objeto SqueezeNet v1.1 que está disponível publicamente no MMS Model Zoo .
Para começar, você precisa do Python, que é o único pré-requisito para o MMS. Se você não possui o Python instalado, instale o Python 2.7 ou 3.6, seguindo as instruções no site Python .
Em seguida, use PyPi para instalar o MMS na sua máquina de escolha. O MMS suporta sistemas operacionais Mac e Linux.
Servir de um modelo é feito simplesmente executando MMS e apontando para um modelo de URL de arquivo ou arquivo local:
Depois de executar este comando, o processo MMS iniciará, baixará e descompactará o arquivo do modelo, configurará o serviço com os artefatos do modelo e começará a ouvir as solicitações recebidas sobre o / squeezenet / predizer o ponto final no localhost, a porta 8080 (host e porta são configuráveis).
Para testar seu serviço recém-criado, vamos enviar uma solicitação de inferência por HTTP, pedindo ao modelo que classifique uma imagem:
Você verá uma resposta semelhante à que segue, com o modelo que identifica o objeto na imagem para ser um “gato egípcio” com 85% de probabilidade. Yay!
Para mergulhar mais profundamente em servir o modelo, confira a documentação do Servidor .
O MMS serve modelos empacotados no formato de arquivo do modelo MMS. Ele inclui uma interface de linha de comando mxnet-model-export para empacotar artefatos de modelos e exportar um arquivo de arquivo de modelo único. O arquivo modelo exportado encapsula todos os artefatos e meta-dados necessários para servir o modelo. É consumido pelo MMS ao inicializar um ponto final de serviço. Nenhum metadado ou recursos adicionais do modelo são necessários para servir.
O diagrama a seguir descreve o processo de exportação:

Conforme mostrado no diagrama, os artefatos obrigatórios necessários para empacotar um arquivo de modelo são a arquitetura de rede neural do modelo e parâmetros (camadas, operadores e pesos), bem como o tipo de dados de entrada e saída de serviço e as definições de forma de tensor. No entanto, usar modelos em casos de uso do mundo real requer mais do que apenas a rede neural. Por exemplo, muitos modelos de visão exigem o pré-processamento e a transformação das imagens de entrada antes de serem alimentados no modelo. Outro exemplo são os modelos de classificação que tipicamente exigem pós processamento para classificar e truncar os resultados da classificação. Para atender a esses requisitos e permitir o encapsulamento completo dos modelos no arquivo do modelo, o MMS pode empacotar o código de processamento personalizado, bem como qualquer arquivo auxiliar no arquivo e disponibilizar esses arquivos no tempo de execução. Com este poderoso mecanismo, você pode gerar arquivos modelo que encapsulam um pipeline de processamento completo: desde as entradas de pré-processamento, até a inferência de customização e até a aplicação de identificadores de etiquetas de classe na saída da rede antes de retornar ao cliente pela rede.
Para saber mais sobre a exportação de arquivos do modelo, confira documentos de exportação do MMS .
O MMS foi projetado para facilidade de uso, flexibilidade e escalabilidade. Ele oferece recursos adicionais além dos discutidos nesta postagem do blog, incluindo a configuração do ponto final de serviço, métricas em tempo real e registro, imagens de contêiner pré-configuradas e muito mais.
Para saber mais sobre o MMS, recomendamos que comece com o tutorial Single Shot MultiBox Detector (SSD) , que o levará a exportar e a servir um modelo SSD. Mais exemplos e documentação adicional estão disponíveis na pasta de documentação do repositório.
À medida que desenvolvemos e ampliamos o MMS, recebemos a participação da comunidade através de perguntas, pedidos e contribuições. Dirija-se ao repositório awslabs / mxnet-model-server para começar!
 +1-786-628-7980
+1-786-628-7980
 Sign Up/Sign In
Sign Up/Sign In