Na semana passada, a comunidade Apache MXNet lançou a versão 0.12 da MXNet. As principais características foram o suporte para GPUs NVIDIA Volta e tensores esparsos . O lançamento também incluiu uma série de novos recursos para a interface de programação Gluon. Em particular, esses recursos facilitam a implementação de pesquisas de ponta em seus modelos de aprendizado profundo:
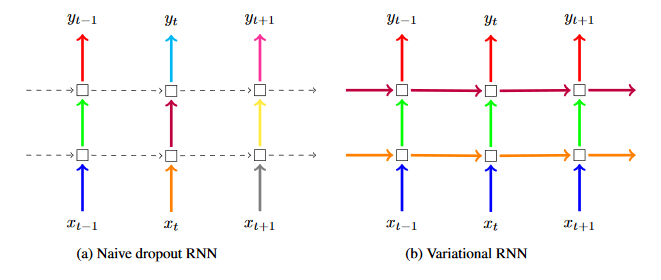
O abandono progressivo (VariationalDropoutCell) baseia-se em pesquisas recentes para fornecer uma nova ferramenta para mitigar a superposição em RNNs. Ele desenha a partir de “A Aplicação Teoramente Aterrada de Redes Neurais Recorrentes” e “RNNDrop: Uma Abordagem Novela para RNNs em ASR”. A superposição é um erro de modelagem em que o modelo está tão próximo ao conjunto de dados de treinamento que diminui sua precisão de predição quando vê novos dados ou o conjunto de dados de teste. Dropout é uma técnica de modelagem que minimiza aleatoriamente os parâmetros do modelo, de modo que o modelo não se torna excessivamente dependente de nenhuma entrada ou parâmetro durante o treinamento. No entanto, esta técnica não foi aplicada com sucesso em RNNs. A pesquisa até o presente momento se concentrou na aplicação do abandono apenas às entradas e saídas com aleatoriedade total no que é zerado em todas as etapas do tempo da RNN. O abandono progressivo elimina essa aleatoriedade em etapas de tempo e aplica a mesma matriz (ou máscara) de abandono aleatório às entradas, saídas e estados ocultos do RNN em cada etapa do tempo.
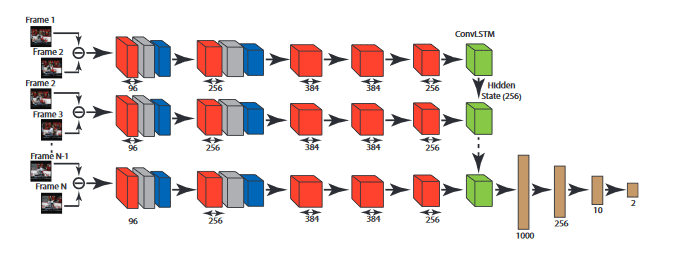
As células RNN, LSTM e GRU convolutionais (por exemplo, Conv1DRNNCell, Conv1DLSTMCell, Conv1DGRUCell) facilitam o modelamento de conjuntos de dados que têm dimensões de sequência e espaciais – por exemplo, vídeos ou imagens capturados ao longo do tempo. Os modelos de LSTM convolucional foram aplicados com sucesso em pesquisas apresentadas em “Rede de LSTM Convolucional: Uma Abordagem de Aprendizagem de Máquina para Precipitação de Nowcasting”. As redes LSTM são projetadas para analisar dados seqüenciais enquanto acompanham as dependências de longo prazo. Eles avançaram o estado da arte no processamento de linguagem natural (PNL). No entanto, eles executam com eficácia limitada quando aplicados em casos de uso espaciotemporal em que o conjunto de dados tem uma dimensão espacial além de exibir uma seqüência baseada no tempo. Exemplos de casos de uso espaciotemporais incluem a previsão do volume total de chuvas em diferentes bolsões de Hong Kong nas próximas seis horas (como discutido no documento de pesquisa referenciado anteriormente) ou detectar se um vídeo é violento . Para o reconhecimento de imagem, as redes neurais convolutivas (CNNs) avançaram o estado da arte aplicando uma operação de convolução em imagens, permitindo que o modelo capture o contexto espacial. RNN convolucional, LSTMs e GRUs incorporam essas operações de convolução nas arquiteturas RNN, LSTM e GRU, respectivamente.
Esta versão do MXNet também expandiu o conjunto de funções de perda suportadas em Gluon por sete: (1) perda sigmoidal de entropia cruzada binária, (2) perda de classificação temporária de conexão (CTC), (3) perda de Huber, (4) perda de dobradiça, (5 ) perda de dobradiça ao quadrado, (6) perda logística e (7) perda tripla. As funções de perda medem o desempenho do seu modelo de acordo com algum objetivo. Essas funções de perda usam diferentes cálculos matemáticos para medir esse desempenho e, portanto, têm diferentes efeitos no processo de otimização durante o treinamento do modelo. Escolher uma função de perda é mais uma arte do que uma ciência, e não há uma heurística simples para decidir qual escolher. Em vez disso, você pode examinar a extensa pesquisa sobre cada uma dessas funções de perda para obter uma perspectiva quando essas funções de perda foram aplicadas com sucesso e quando não tão bem sucedidas.
Esta versão também apresenta adições úteis como uma API de exportação e uma propriedade de taxa de aprendizado para a função otimizador de treinador. A API de exportação permite exportar a arquitetura do modelo de rede neural e os parâmetros do modelo associados para um formato intermediário que pode ser usado para carregar o modelo em um ponto posterior ou em um local diferente. Esta API ainda é experimental, então todas as funcionalidades ainda não são suportadas. Além disso, agora você pode definir e ler a taxa de aprendizado usando a propriedade de treinamento de aprendizado recentemente adicionada do treinador.
Começar com MXNet é simples, e uma lista completa de mudanças nesta versão pode ser encontrada nas notas de versão . Para saber mais sobre a interface Gluon, visite a página de detalhes do MXNet ou os tutoriais .
 Vikram Madan é um Gerente Sênior de Produto para AWS Deep Learning. Ele trabalha em produtos que tornam os mecanismos de aprendizado profundo mais fáceis de usar com um foco específico no mecanismo Apache MXNet de código aberto. Em seu tempo livre, ele gosta de correr longas distâncias e assistir documentários.
Vikram Madan é um Gerente Sênior de Produto para AWS Deep Learning. Ele trabalha em produtos que tornam os mecanismos de aprendizado profundo mais fáceis de usar com um foco específico no mecanismo Apache MXNet de código aberto. Em seu tempo livre, ele gosta de correr longas distâncias e assistir documentários.
 +1-786-628-7980
+1-786-628-7980
 Sign Up/Sign In
Sign Up/Sign In